Now Issue the following query "select * from emptable where age BETWEEN 16 AND 19".This will fetch me the following data.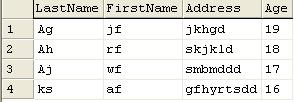
But the point of concern here is performance and the usage of indices.To knows it I enquired for the estimated execution Plan.
It shows as below: Here it is scanning the table which is organized by the Clustered index. This is very much simil ar to table scan. The cost field
ar to table scan. The cost field shows 0.03767 units.
shows 0.03767 units.
With an Index on Age field
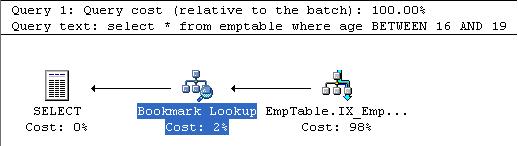
Try to create an index on the column Age. Issue the previous query again, now, the estimated execution Plan is shown as below. It is split into to two tasks
1) Index Seek
Index seek goes through the Index structure which we created for the column and notes down the ROWIDs or Clustering Keys of the rows in table matching the selection criteria.
2) BookMark Lookup. Uses this ROWIDs or Clustering Keys to fetch the actual row in the table.
The cost field shows: 0.00651 units.
1) Index Seek
Index seek goes through the Index structure which we created for the column and notes down the ROWIDs or Clustering Keys of the rows in table matching the selection criteria.
2) BookMark Lookup. Uses this ROWIDs or Clustering Keys to fetch the actual row in the table.
The cost field shows: 0.00651 units.


How it works
When the query is passed to the database, based on the columns in the WHERE clause fields are compared against existing indices. In our case the WHERE clause contains the age and it matches the just now created Index. So it is should be selected.
The index structure will usually be some variant of B/B+ tree, with each node contains a pointer called ROWID or Clustering Key pointing to the physical location of the row in the table. This pointer can be used during the BookMark Lookup phase to fetch the row.
Obviously going through the Tree structure is quicker compared to scanning the entire table. Hence using indices will improve the performance.
Obviously going through the Tree structure is quicker compared to scanning the entire table. Hence using indices will improve the performance.



No comments:
Post a Comment